
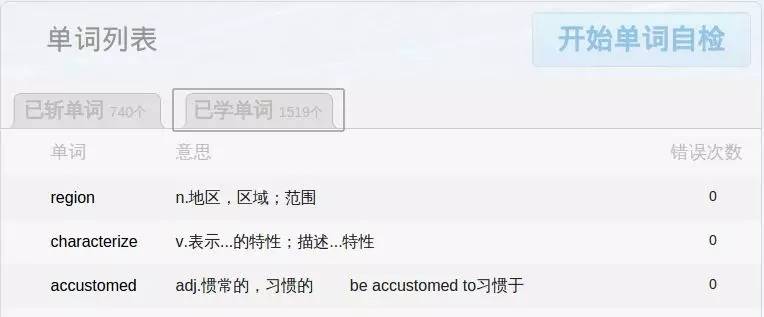
 百词斩会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住。我们来用Python来爬取这些信息,同时学习Python爬虫基础。
百词斩会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住。我们来用Python来爬取这些信息,同时学习Python爬虫基础。
首先来到百词斩网站,这个网站是需要登录的,不过还好没验证码,我们可以先看下在登录过程中浏览器POST了哪些数据。打开浏览器开发工具(F12),以Chrome浏览器为例,记录登录过程中浏览器的Network情况:
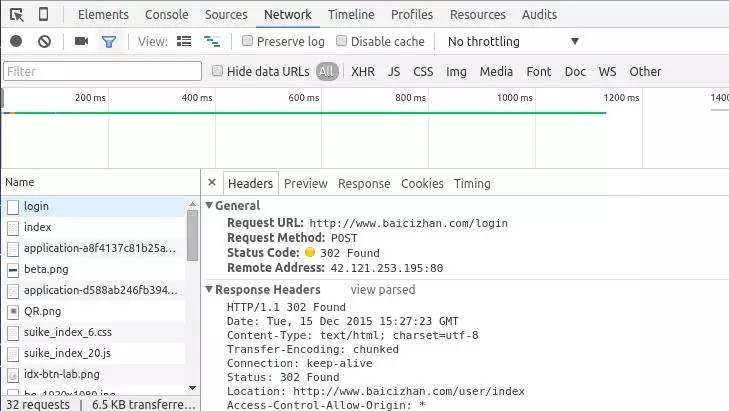
我们可以发现,在登录过程中,浏览器向http://www.baicizhan.com/login以POST方式提交了数据。提交了什么数据呢?我们可以在下面的Form Data里看到。

其中,email是用户名,raw_pwd就是密码,这里的数据是需要经过URL编码的,我们可以点view URL encoded查看编码后的样子。URL编码需要urllib库。
在请求头(Request Headers)部分,我们还看到了Cookie。因此,我们还需要cookie库,来处理我们的Cookie。

1 import urllib
2 import urllib2
3 import cookielib
4
5 email = 'your_email'
6 pwd = 'your_password'
7 data = {'email':email,'raw_pwd':pwd}
8 post_data = urllib.urlencode(data)
9
10 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookielib.CookieJar()))
11
12 response = opener.open('http://www.baicizhan.com/login', post_data)
13 print(response.read())

这样,我们可以发现,打印的是登录后的页面源码,这说明我们成功实现了登录。
接着,我们来分析下单词列表的页面:

当我们点击页码时,实际上是发送了GET请求。然后我们看Response,发现是个json,我们解析下看看

如果要在Python中解析json,我们需要json库。我们打印下前两页的单词看看:

1 import urllib2
2 import cookielib
3 import urllib
4 import json
5
6 email = 'your_email'
7 pwd = 'your_password'
8 data = {'email':email,'raw_pwd':pwd}
9 post_data = urllib.urlencode(data)
10
11 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookielib.CookieJar()))
12
13 opener.open('http://www.baicizhan.com/login', post_data)
14
15 for i in range(1, 3):
16 content = json.loads(opener.open("http://www.baicizhan.com/user/all_done_words_list?page=%s"%i).read())
17 for word in content["list"]:
18 print word["word"]
19 print word["word_meaning"].strip()
20 print word["wrong_times"]

这样,我们就能打印出前两页的单词以及释义、错误次数。
至于要把所有已学单词都获取到,只需要稍作修改即可,之后我们便能把这些数据存储进行一些后续的处理。
文章来源: 松勤软件学院
原文链接: https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzI3NDc4NTQ0Nw==&scene=126#wechat_redirect



-
 党课思想汇报:https://www.nanss.com/xuexi/16665.html 谢师宴邀请函:https://www.nanss.com/xuexi/13104.html 弹簧地板:https://www.nanss.com/shenghuo/16107.html 考勤管理:https://www.nanss.com/gongzuo/14609.html 读书征文:https://www.nanss.com/xuexi/15414.html 开国大典观后感:https://www.nanss.com/xuexi/15890.html 情感日记:https://www.nanss.com/yuedu/14420.html 安全玻璃:https://www.nanss.com/shenghuo/16068.html 故事的力量:https://www.nanss.com/xuexi/14544.html 三年级科学教学计划:https://www.nanss.com/xuexi/16646.html 300作文免费可抄:https://www.nanss.com/xuexi/14956.html 儿童英文故事:https://www.nanss.com/yuedu/15241.html 认识实习报告:https://www.nanss.com/xuexi/14652.html 会计职业生涯规划:https://www.nanss.com/xuexi/16269.html 教育心得:https://www.nanss.com/xuexi/15703.html 大病救助申请书:https://www.nanss.com/gongzuo/15426.html 幼儿园个人总结:https://www.nanss.com/gongzuo/16872.html 党员管理制度:https://www.nanss.com/xuexi/14116.html 工作失误检讨书:https://www.nanss.com/gongzuo/15358.html 应聘简历模板:https://www.nanss.com/gongzuo/15172.html 初三作文600字:https://www.nanss.com/xuexi/14381.html 最美乡村教师事迹:https://www.nanss.com/gongzuo/16983.html 水瓶座男生性格特点:https://www.nanss.com/xingzuo/15118.html 调研报告模板:https://www.nanss.com/gongzuo/16697.html 推荐一本书作文400字:https://www.nanss.com/xuexi/16844.html 大学生职业发展规划:https://www.nanss.com/xuexi/14458.html 安徒生童话故事:https://www.nanss.com/yuedu/16546.html 我和孙悟空过一天作文300字:https://www.nanss.com/xuexi/16507.html 课程设计小结:https://www.nanss.com/xuexi/16818.html 国庆日记:https://www.nanss.com/xuexi/14351.html(0) 回复 (0)
党课思想汇报:https://www.nanss.com/xuexi/16665.html 谢师宴邀请函:https://www.nanss.com/xuexi/13104.html 弹簧地板:https://www.nanss.com/shenghuo/16107.html 考勤管理:https://www.nanss.com/gongzuo/14609.html 读书征文:https://www.nanss.com/xuexi/15414.html 开国大典观后感:https://www.nanss.com/xuexi/15890.html 情感日记:https://www.nanss.com/yuedu/14420.html 安全玻璃:https://www.nanss.com/shenghuo/16068.html 故事的力量:https://www.nanss.com/xuexi/14544.html 三年级科学教学计划:https://www.nanss.com/xuexi/16646.html 300作文免费可抄:https://www.nanss.com/xuexi/14956.html 儿童英文故事:https://www.nanss.com/yuedu/15241.html 认识实习报告:https://www.nanss.com/xuexi/14652.html 会计职业生涯规划:https://www.nanss.com/xuexi/16269.html 教育心得:https://www.nanss.com/xuexi/15703.html 大病救助申请书:https://www.nanss.com/gongzuo/15426.html 幼儿园个人总结:https://www.nanss.com/gongzuo/16872.html 党员管理制度:https://www.nanss.com/xuexi/14116.html 工作失误检讨书:https://www.nanss.com/gongzuo/15358.html 应聘简历模板:https://www.nanss.com/gongzuo/15172.html 初三作文600字:https://www.nanss.com/xuexi/14381.html 最美乡村教师事迹:https://www.nanss.com/gongzuo/16983.html 水瓶座男生性格特点:https://www.nanss.com/xingzuo/15118.html 调研报告模板:https://www.nanss.com/gongzuo/16697.html 推荐一本书作文400字:https://www.nanss.com/xuexi/16844.html 大学生职业发展规划:https://www.nanss.com/xuexi/14458.html 安徒生童话故事:https://www.nanss.com/yuedu/16546.html 我和孙悟空过一天作文300字:https://www.nanss.com/xuexi/16507.html 课程设计小结:https://www.nanss.com/xuexi/16818.html 国庆日记:https://www.nanss.com/xuexi/14351.html(0) 回复 (0) -
讨债公司/蓝月传奇辅助/蓝月辅助(0) 回复 (0)
-
讨债公司 搬家公司 网站制作(0) 回复 (0)


