
读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)file-like Object
像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行。StringIO就是在内存中创建的file-like Object,常用作临时缓冲。
open()函数将会返回一个file对象,基本语法如下:
open(filename,mode)
filename:传入文件的路径
mode决定了打开文件的模式:只读,写入,追加等,这个参数默认是只读
r表示只读,文件指针在文件开头
w表示写入,如果文件存在就打开并从头开始编辑,即原来的内容会被删除,如果不存在就新建
a表示追加,如果文件已存在,新的内容会写到已有内容之后。如果文件不存在,则新建
b表示,以二进制打开文件,进行读写或追加,可以和r,w,a一起用
+表示读和写,可以和r,w,a一起用
所以mode可以传入r,r+,rb,rb+,w和a也是以此类推
写文件
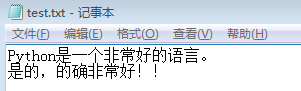
f = open('C:/Users/ms/Desktop/test.txt','w')#打开一个文件
文件路径是/,从windows拷贝过来是\
num = f.write("Python是一个非常好的语言。\n是的,的确非常好!!\n")
print(num)#write()返回的是写入的字符数量
f.close()#关闭文件

如果写入的不是字符串,需要用str()转换成字符串
可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。
Python引用with自动帮忙调用close()方法
with open('C:/Users/ms/Desktop/test.txt','w') as f:
f.write("Python是一个非常好的语言。\n是的,的确非常好!!\n")
如果文件打开模式带 b,那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,
否则报错:TypeError: a bytes-like object is required, not 'str'。
#with open('C:/Users/ms/Desktop/test.txt','wb') as f:
#f.write(("Python是一个非常好的语言。\n是的,的确非常好!!\n").encode('utf-8'))
读文件
要以读文件的模式打开一个文件对象,使用Python内置的open()函数,传入文件名和标识符
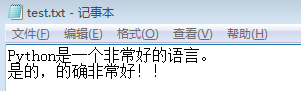
f = open('C:/Users/ms/Desktop/test.txt','r')
如果文件不存在,open()函数会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在
str = f.read()#Python把内容读到内存,用一个str对象表示
print(str)
f.close()

最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
由于文件读写时都可能产生IOError,一旦出错,后面的f.close()就不会调用,用了保证无论是否出错都能正确的关闭文件,我们可以用try...finally来实现,但是每次这样写实在太繁琐了,还是使用with语句来帮忙自动调用close()方法
with open('C:/Users/ms/Desktop/test.txt','r')as f:
print(f.read())
调用read()会一次性读取文件的全部内容,如果文件内容过大,内存就爆了,所以为了保险起见可以反复调用read(size)方法,每次最多读取size个字节的内容
with open('C:/Users/ms/Desktop/test.txt','r')as f:
print(f.read(10))
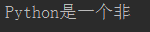
这样只会读10个字节的内容
readline() 会从文件中读取单独的一行。换行符为 '\n'
with open('C:/Users/ms/Desktop/test.txt','r') as f:
print(f.readline())

调用readlines()一次读取所有内容并按行返回list
with open('C:/Users/ms/Desktop/test.txt','r') as f:
print(f.readlines())

返回的是个数组,会把换行以\n返回
with open('C:/Users/ms/Desktop/test.txt','r') as f:
for line in f.readlines():#读取每行
print(line.strip())#strip方法去掉每行头尾空白

字符编码
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如读取GBK编码文件
with open('C:/Users/ms/Desktop/test.txt','r',encoding='gbk'):f
print(f.read)
#遇到有些编码不规范的文件,可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,需要给open()函数传入errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
with open('C:/Users/ms/Desktop/test.txt','r',encoding='gbk',errors='ignore'):f
print(f.read)
tell()函数返回文件对象当前所处的位置,从文件开头算起的字节数
with open('C:/Users/ms/Desktop/test.txt','r') as f:
f.read(10)
print(f.tell())

如果要改变当前位置,可以使用f.seek(offset, from_what)函数
offset: 偏移量,需要向前或向后的字节数,正为向后,负为向前
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾
seek(x,0) :从起始位置即文件首行首字符开始移动 x 个字符
seek(x,1) :表示从当前位置往后移动x个字符
#eek(-x,2):表示从文件的结尾往前移动x个字符
用seek方法时,需注意,如果你打开的文件没有用'b'的方式打开,则offset无法使用负值哦
with open('C:/Users/ms/Desktop/test1.txt','rb+') as f:#需要自己在桌面新建test1.txt
f.write(b'0123456789abcdef')
print(f.seek(5))#移动到文件的第六个字节
print(f.read(1))
print(f.seek(-3,2))#移动到文件的倒数第三字节
print(f.read(1))

文章来源: 松勤网



-
 栗子怎么煮好吃又好剥皮:https://www.nanss.com/shenghuo/11432.html 八种情况表明你该辞职了:https://www.nanss.com/gongzuo/12165.html 写给母校的一封信:https://www.nanss.com/xuexi/12955.html 我想对你说作文600字:https://www.nanss.com/xuexi/13013.html 描写学校的作文:https://www.nanss.com/xuexi/11561.html 快乐来自:https://www.nanss.com/xuexi/12602.html 烛光赞作文:https://www.nanss.com/xuexi/12008.html 决议范文:https://www.nanss.com/gongzuo/13537.html 情人节送什么礼物:https://www.nanss.com/shenghuo/12302.html 有何特长怎么写:https://www.nanss.com/wenti/11463.html supply的用法:https://www.nanss.com/xuexi/11217.html 温暖作文600字:https://www.nanss.com/xuexi/11351.html 年中工作总结个人:https://www.nanss.com/gongzuo/12703.html 螨虫最怕这3种东西:https://www.nanss.com/shenghuo/11705.html 烟的网名:https://www.nanss.com/mingcheng/12463.html 文艺晚会串词:https://www.nanss.com/gongzuo/13560.html 贺信格式:https://www.nanss.com/xuexi/13298.html 稳重的网名:https://www.nanss.com/mingcheng/11925.html 英语电影观后感:https://www.nanss.com/xuexi/12277.html 职务说明书:https://www.nanss.com/gongzuo/13090.html 羽毛球比赛规则:https://www.nanss.com/shenghuo/13971.html 毕业生实习鉴定表:https://www.nanss.com/xuexi/12783.html 入党推荐书:https://www.nanss.com/xuexi/13242.html 在天晴了的时候仿写:https://www.nanss.com/xuexi/12595.html 党员身份证明:https://www.nanss.com/shenghuo/13228.html 什么专业就业前景好:https://www.nanss.com/xuexi/12235.html 描写人的四字词语:https://www.nanss.com/xuexi/11638.html 高三励志:https://www.nanss.com/xuexi/13905.html 行政工作主要负责什么:https://www.nanss.com/gongzuo/12313.html 车辆转让协议:https://www.nanss.com/shenghuo/12724.html(0) 回复 (0)
栗子怎么煮好吃又好剥皮:https://www.nanss.com/shenghuo/11432.html 八种情况表明你该辞职了:https://www.nanss.com/gongzuo/12165.html 写给母校的一封信:https://www.nanss.com/xuexi/12955.html 我想对你说作文600字:https://www.nanss.com/xuexi/13013.html 描写学校的作文:https://www.nanss.com/xuexi/11561.html 快乐来自:https://www.nanss.com/xuexi/12602.html 烛光赞作文:https://www.nanss.com/xuexi/12008.html 决议范文:https://www.nanss.com/gongzuo/13537.html 情人节送什么礼物:https://www.nanss.com/shenghuo/12302.html 有何特长怎么写:https://www.nanss.com/wenti/11463.html supply的用法:https://www.nanss.com/xuexi/11217.html 温暖作文600字:https://www.nanss.com/xuexi/11351.html 年中工作总结个人:https://www.nanss.com/gongzuo/12703.html 螨虫最怕这3种东西:https://www.nanss.com/shenghuo/11705.html 烟的网名:https://www.nanss.com/mingcheng/12463.html 文艺晚会串词:https://www.nanss.com/gongzuo/13560.html 贺信格式:https://www.nanss.com/xuexi/13298.html 稳重的网名:https://www.nanss.com/mingcheng/11925.html 英语电影观后感:https://www.nanss.com/xuexi/12277.html 职务说明书:https://www.nanss.com/gongzuo/13090.html 羽毛球比赛规则:https://www.nanss.com/shenghuo/13971.html 毕业生实习鉴定表:https://www.nanss.com/xuexi/12783.html 入党推荐书:https://www.nanss.com/xuexi/13242.html 在天晴了的时候仿写:https://www.nanss.com/xuexi/12595.html 党员身份证明:https://www.nanss.com/shenghuo/13228.html 什么专业就业前景好:https://www.nanss.com/xuexi/12235.html 描写人的四字词语:https://www.nanss.com/xuexi/11638.html 高三励志:https://www.nanss.com/xuexi/13905.html 行政工作主要负责什么:https://www.nanss.com/gongzuo/12313.html 车辆转让协议:https://www.nanss.com/shenghuo/12724.html(0) 回复 (0) -
讨债公司/蓝月传奇辅助/蓝月辅助(0) 回复 (0)
-
讨债公司 搬家公司 蓝月传奇辅助(0) 回复 (0)


