
相信大家都有在看小说的时候被频繁弹出的广告骚扰而感到烦不胜烦,今天给大家带来一个小爬虫程序,帮助大家摆脱广告的骚扰,不过只可以爬取免费小说的哦!接下来就是正文部分啦!
首先我们要明确我们的设计思路
1、我们要确定我们要爬取的网页的url地址
2、获取小说目录,目录页面源代码
3、获取目录章节href
4、获取小说章节内容
5、下载小说
那么我们要怎么获取我们想要的url地址呢?首先我们打开一个小说的网站,找到自己需要爬取的小说点击链接进入到章节目录页面。我们按F12进入到开发者工具。
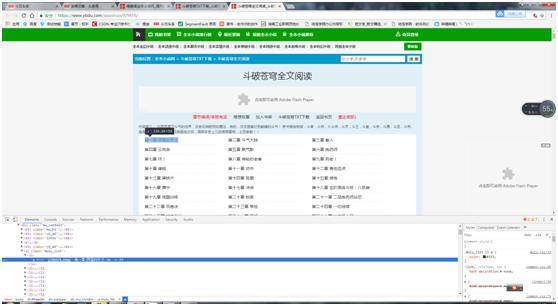
这个时候我们会看到一个1796979.html的地址,但是这个地址明显是不可以用的,当我们的光标停留在上面的时候,我们会看到一个详细的地址,我们会发现我们的章节详情的url地址是有规律的
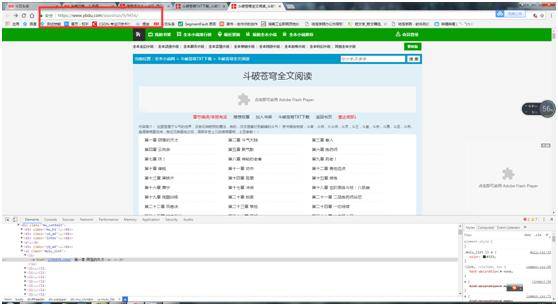
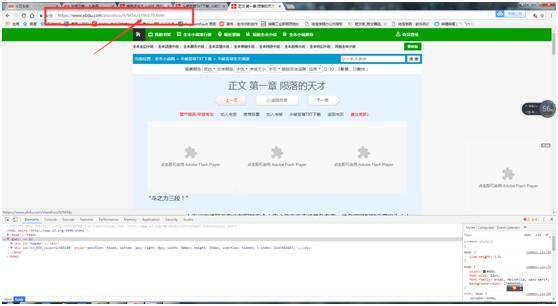
我们会发现这两个字符串拼接起来就是我们需要的url了!
好了,接下来就是我们的代码阶段了新建一个python项目,名字就叫getNovelContent吧!
首先我们要获取目录章节的源代码。如图:

接下我们需要获取我们的目录章节

这就是我们获取目录章节的源码,接下来,我们需要遍历urls,把存储到里面的数据显示出来。首先我们要获取章节,和拼接url源码如图所示:

然后就是获取我们的章节内容,获取我们章节内容的时候我们要记得看一下内容的编码格式进行解码!接下来我们把获得的html进行转义。我们使用xpath的方式来获取小说内容,xpath可以在开发者工具里面直接复制出来,然后我们用一个for循环把/xa0替换掉!
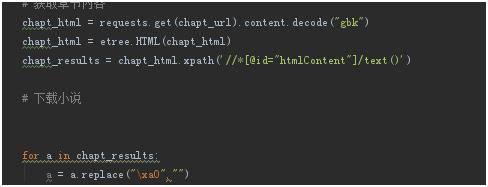
最后一步就是下载我们的小说了!源代码如图:
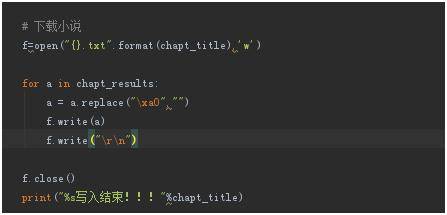
然后我们的一个爬虫小程序就完成啦!是不是很简单啦?
文章来源: 松勤软件学院
原文链接: https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzI3NDc4NTQ0Nw==&scene=126#wechat_redirect



- 还没有人评论,欢迎说说您的想法!


